


Natural Language Processing (NLP) is the branch of Artificial Intelligence (AI) that gives the ability to machine understand and process human languages. Human languages can be in the form of text or audio format.
Applications of NLP
The applications of Natural Language Processing are as follows:
Voice Assistants like Alexa, Siri, and Google Assistant use NLP for voice recognition and interaction.
Tools like Grammarly, Microsoft Word, and Google Docs apply NLP for grammar checking and text analysis.
Information extraction through Search engines such as Google and DuckDuckGo.
Website bots and customer support chatbots leverage NLP for automated conversations and query handling.
Google Translate and similar services use NLP for real-time translation between languages.
Text summarization
Phases of Natural Language Processing
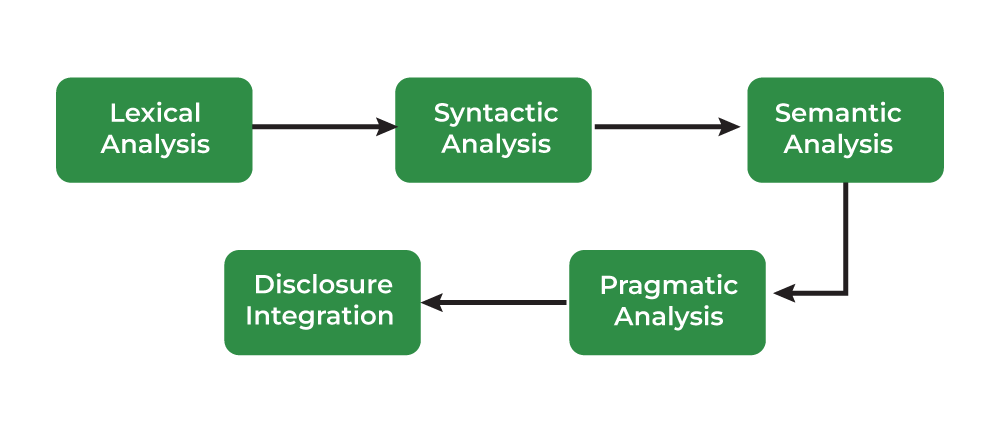
There are two components of Natural Language Processing:
Natural Language Understanding
Natural Language Generation
Libraries for Natural Language Processing
Some of natural language processing libraries include:
NLTK (Natural Language Toolkit)
spaCy
Transformers (by Hugging Face)
Gensim
Normalizing Textual Data in NLP
Text Normalization transforms text into a consistent format improves the quality and makes it easier to process in NLP tasks.
Key steps in text normalization includes:
1. Regular Expressions (RE) are sequences of characters that define search patterns.
2. Tokenization is a process of splitting text into smaller units called tokens.
3. Lemmatization reduces words to their base or root form.
4. Stemming reduces works to their root by removing suffixes. Types of stemmers include:
5. Stopword removal is a process to remove common words from the document.
6. Parts of Speech (POS) Tagging assigns a part of speech to each word in sentence based on definition and context.
Text Representation or Text Embedding Techniques in NLP
Text representation converts textual data into numerical vectors that are processed by the following methods:
One-Hot Encoding
Bag of Words (BOW)
N-Grams
Term Frequency-Inverse Document Frequency (TF-IDF)
N-Gram Language Modeling with NLTK
Text Embedding Techniques refer to the methods and models used to create these vector representations, including traditional methods (like TFIDF and BOW) and more advanced approaches:
1. Word Embedding
Word2Vec (SkipGram, Continuous Bag of Words – CBOW)
GloVe (Global Vectors for Word Representation)
fastText
2. Pre-Trained Embedding
ELMo (Embeddings from Language Models)
BERT (Bidirectional Encoder Representations from Transformers)
3. Document Embedding – Doc2Vec
Deep Learning Techniques for NLP
Deep learning has revolutionized Natural Language Processing (NLP) by enabling models to automatically learn complex patterns and representations from raw text. Below are some of the key deep learning techniques used in NLP:
Artificial Neural Networks (ANNs)
Recurrent Neural Networks (RNNs)
Long Short-Term Memory (LSTM)
Gated Recurrent Unit (GRU)
Seq2Seq Models
Transformer Models
Pre-Trained Language Models
Pre-trained models understand language patterns, context and semantics. The provided models are trained on massive corpora and can be fine tuned for specific tasks.
GPT (Generative Pre-trained Transformer)
Transformers XL
T5 (Text-to-Text Transfer Transformer)
RoBERTa
Natural Language Processing Tasks
1. Text Classification
2. Information Extraction
3. Sentiment Analysis
4. Machine Translation
5. Text Summarization
6. Text Generation
History of NLP
Natural Language Processing (NLP) emerged in 1950 when Alan Turing published his groundbreaking paper titled Computing Machinery and Intelligence. Turing’s work laid the foundation for NLP, which is a subset of Artificial Intelligence (AI) focused on enabling machines to automatically interpret and generate human language. Over time, NLP technology has evolved, giving rise to different approaches for solving complex language-related tasks.
1. Heuristic-Based NLP
The Heuristic-based approach to NLP was one of the earliest methods used in natural language processing. It relies on predefined rules and domain-specific knowledge. These rules are typically derived from expert insights. A classic example of this approach is Regular Expressions (Regex), which are used for pattern matching and text manipulation tasks.
2. Statistical and Machine Learning-Based NLP
As NLP advanced, Statistical NLP emerged, incorporating machine learning algorithms to model language patterns. This approach applies statistical rules and learns from data to tackle various language processing tasks. Popular machine learning algorithms in this category include:
Naive Bayes
Support Vector Machines (SVM)
Hidden Markov Models (HMM)
3. Neural Network-Based NLP (Deep Learning)
The most recent advancement in NLP is the adoption of Deep Learning techniques. Neural networks, particularly Recurrent Neural Networks (RNNs), Long Short-Term Memory Networks (LSTMs), and Transformers, have revolutionized NLP tasks by providing superior accuracy. These models require large amounts of data and considerable computational power for training
FAQs on Natural Language Processing
What is the most difficult part of natural language processing?
Ambiguity is the main challenge of natural language processing because in natural language, words are unique, but they have different meanings depending upon the context which causes ambiguity on lexical, syntactic, and semantic levels.
What are the 4 pillars of NLP?
The four main pillars of NLP are 1.) Outcomes, 2.) Sensory acuity, 3.) behavioural flexibility, and 4.) report.
What language is best for natural language processing?
Python is considered the best programming language for NLP because of their numerous libraries, simple syntax, and ability to easily integrate with other programming languages.
What is the life cycle of NLP?
There are four stages included in the life cycle of NLP – development, validation, deployment, and monitoring of the models.